- Forum
- Windows Programming
- How to Proxychain properly with WinSocks
How to Proxychain properly with WinSocks?
Hello there,
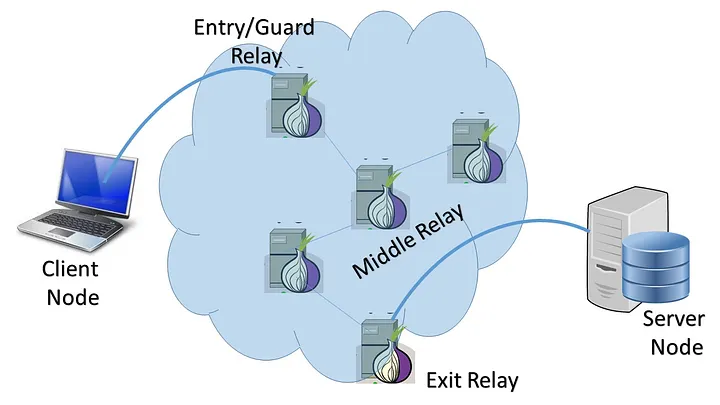
ive been working on a school project to demonstrate the (onion routing like) process of Proxychaining with C++ and WinSocks from Scratch and i ran into knowledge gap on how to connect to the second Proxy over Proxy 1 by somewhat sending a command to Proxy 1 to connect to Proxy 2, because Proxy 2 shalt not know the original address but only Proxy 1's one.
So to see wheather this workes ive decided to connect to httpbin.org/ip with GET to get back the response to see which ip showed up on httpbin.
Hopefully something like that:
I am using Socks-5 Proxies:
which i have found on https://spys.one/en/socks-proxy-list/
Now i reached the limit of my knowledge how to achieve that Proxy 2 and how to make sure its sending the response back to me over Proxy 1..
I would not have bothered you if I had gotten anywhere else or with ChatPGT, but even GPT is at its limit there and could not help me.
Source Code:
I have commented a bit to make the code more readable for you.
This code does not currently link the two proxies correctly (l.55) .
Do you have an idea how i can achieve that?
Thank you all in advance,
Luke
ive been working on a school project to demonstrate the (onion routing like) process of Proxychaining with C++ and WinSocks from Scratch and i ran into knowledge gap on how to connect to the second Proxy over Proxy 1 by somewhat sending a command to Proxy 1 to connect to Proxy 2, because Proxy 2 shalt not know the original address but only Proxy 1's one.
So to see wheather this workes ive decided to connect to httpbin.org/ip with GET to get back the response to see which ip showed up on httpbin.
Hopefully something like that:
|
|
I am using Socks-5 Proxies:
|
|
which i have found on https://spys.one/en/socks-proxy-list/
Now i reached the limit of my knowledge how to achieve that Proxy 2 and how to make sure its sending the response back to me over Proxy 1..
I would not have bothered you if I had gotten anywhere else or with ChatPGT, but even GPT is at its limit there and could not help me.
Source Code:
|
|
I have commented a bit to make the code more readable for you.
This code does not currently link the two proxies correctly (l.55) .
Do you have an idea how i can achieve that?
Thank you all in advance,
Luke
Last edited on
| Now i reached the limit of my knowledge how to achieve that Proxy 2 and how to make sure its sending the response back to me over Proxy 1.. |
I think, in a chain of proxy servers, each proxy normally only "knows" about its direct predecessor. Therefore, proxy #2 doesn't know anything about you. It only knows that it go a request from proxy #1 – proxy #2 actually doesn't know that proxy #1 is a proxy; from the view of proxy #2, proxy #1 is just an arbitrary client – and therefore proxy #2 automatically/unavoidably sends its response back to proxy #1.
Consequently, you totally have to rely on proxy #1 to forward the response of proxy #2 back to you.
Note: There is an important difference between "Onion routing" and simple chaining of proxy servers: In Onion routing, the request (and response) use multiple layers of encryption, arranged carefully in such a way that each "node" (proxy) along the chain can only remove one layer of encryption. This makes sure that each "node" can only learn its direct predecessor and its direct successor, but neither the original source nor the final destination, because it can't further decrypt the packet it received (it can only forward it to the next node).
In a simple chaining of proxy servers, you don't have those multiple layers of encryption. So, even the first proxy in the chain – if it is malicious – could easily determine the final destination, by fully inspecting/unwrapping the request that it got from you...
(The actual contents may be protected by SSL/TLS, but that doesn't protect you from a malicious proxy learning the real destination!)
Last edited on
My connection will be end to end - encrypted. This is just to make it work and i dont care about encryption yet, whilst there is no sensitive data. But what is wrong with this code?
I cound not figure it out.
I cound not figure it out.
Last edited on
I'm not an expert on SOCKS5, but what exactly is your problem? Did you try to break it down step by step?
I mean: Does your code using WinSocks work, when you simply connect to the final HTTP-Server directly? That's the first thing you should verify! If so, does it still work, if you add just a single SOCKS5 proxy? If so, what changes if you try to add the second SOCKS5 proxy?
If any of the above doesn't work, what exactly is the "problem" that you are running into?
I suggest to implement/test/fix this step by step, not all at once 😏
BTW: End-to-end encryption doesn't help at all for "anonymity", because only the innermost stream would be encrypted – allowing any proxy along the way to figure out the full route and the final destination. They can't look into the actual payloads, as they are encrypted, but that's not the point! If you want "anonymity", as in Tor, what you need are multiple layers of encryption. That is the idea of "Onion routing".
BTW2: It may be helpful to use a tool like WireShark to see what is really going on, on the wire:
https://www.wireshark.org/
I mean: Does your code using WinSocks work, when you simply connect to the final HTTP-Server directly? That's the first thing you should verify! If so, does it still work, if you add just a single SOCKS5 proxy? If so, what changes if you try to add the second SOCKS5 proxy?
If any of the above doesn't work, what exactly is the "problem" that you are running into?
I suggest to implement/test/fix this step by step, not all at once 😏
BTW: End-to-end encryption doesn't help at all for "anonymity", because only the innermost stream would be encrypted – allowing any proxy along the way to figure out the full route and the final destination. They can't look into the actual payloads, as they are encrypted, but that's not the point! If you want "anonymity", as in Tor, what you need are multiple layers of encryption. That is the idea of "Onion routing".
BTW2: It may be helpful to use a tool like WireShark to see what is really going on, on the wire:
https://www.wireshark.org/
Last edited on
Thank you for your valuable guidance.
Using just a single Socks5 proxy has proven effective, yielding the expected results. My intention was for it to emulate the basic operational principles of onion routing.
Could you kindly elaborate on your point about
?
My understanding was that each subsequent proxy is only aware of the source of its immediate predecessor and its next destination.
Wouldn't the process be the same when using only one proxy?
Here's the version of my code that enabled me connection through a single proxy:
output:
Using just a single Socks5 proxy has proven effective, yielding the expected results. My intention was for it to emulate the basic operational principles of onion routing.
Could you kindly elaborate on your point about
| allowing any proxy along the way to figure out the full route and the final destination |
My understanding was that each subsequent proxy is only aware of the source of its immediate predecessor and its next destination.
Wouldn't the process be the same when using only one proxy?
Here's the version of my code that enabled me connection through a single proxy:
|
|
output:
|
|
Last edited on
ould you kindly elaborate on your point aboutallowing any proxy along the way to figure out the full route and the final destination? My understanding was that each subsequent proxy is only aware of the source of its immediate predecessor and its next destination. |
If you use a single proxy, it unavoidable needs to know the actual source IP address and the actual destination IP address.
Encrypting the payload, e.g. with HTTPS, doesn't change anything about this.
By chaining multiple proxies, each proxy in the chain ideally only knows its immediate predecessor and its immediate successor.
(Only the "entry" and "exit" nodes need to know the actual source and destination IP address, respectively)
https://miro.medium.com/v2/resize:fit:720/format:webp/1*j2aTFBQTd9e1PlFDjeKw1g.jpeg
{kind=link}
But: In general, there is absolutely nothing that prevents an "evil" proxy to look at the nested packets/data and figure out the full route!
Again, encrypting only the payload (innermost packet/layer), e.g. with HTTPS, doesn't change anything about this.
That is why "onion routing", e.g. Tor, uses multiple layers of encryption, so that each proxy along the chain can only remove the "outermost" (at this point of the chain) layer of encryption, in order to figure out the next node, but can not decrypt the nested data any further.
https://upload.wikimedia.org/wikipedia/commons/thumb/e/e1/Onion_diagram.svg/1024px-Onion_diagram.svg.png
{kind=link}
HTTPS is still used (usually), but only at the "innermost" layer that goes to the final destination server.
To my understanding, SOCKS5 does not use any form of encryption, even though it can pass trough an encrypted stream (e.g HTTPS). This means that when you extend the chain from the first SOCKS proxy to the second one, then the first proxy can "see" (as plain text!) the SOCKS packet/header that is to be passed to the second proxy. Hence, the first proxy learns the IP address of the final destination 😱
|
Be aware that, as far as
SOCK_STREAM (TCP/IP) is concerned, a single call to recv() is not guaranteed to give you the full response packet/message! Instead, recv() reads up to n bytes from the stream, but fewer bytes may be read – which may very well be an "incomplete" packet/message. There also is absolutely no guarantee that recv() will stop reading right after the SOCKS response.TCP/IP is a contiguous streams of bytes. Therefore, message boundaries have to be implemented in higher level protocols.
In general, you have to call
recv() in a loop, until the expected number of bytes have been received/accumulated. If the length of the message is not fixed (known beforehand), you have to keep on reading until the "end of message" indicator has been received. For example, in HTTP the end of the "header" is indicated by \r\n\r\n, and the length of the "body" is limited by the Content-Length: header field.Anyway, if
recv() returns more bytes than expected (for the current packet/message), you must not simply ignore/discard those bytes, because they probably belong to whatever packet/message comes next in the TCP/IP stream...https://stackoverflow.com/a/41383398
Last edited on
Thank you for the fantastic explanation. I now understand better what that means. :)
Topic archived. No new replies allowed.