- Forum
- General C++ Programming
- Word Stats (frequency, order)
Word Stats (frequency, order)
I have been completing an assignment were I need to make a console that loads a text file called banned.txt into a bannedText array. I have done this.
I then had to load the words within a 'text1.txt' file and compare this with the banned words. If text1 contained a band word, the banned word is filtered out.
I was also given text2.txt, text3.txt and text4.txt. I needed to do the same with them all.
Here is what I have so far
http://i.gyazo.com/53ab68417ffc274a99767113d1c7c2b2.png
When i select '2' this is shown, the banned words filter perfectly.
http://i.gyazo.com/9fdb7086f8d54394cdcec8f071e606e5.png
The Problem
I have been asked to do the following.
I currently have no idea how to go about this.
Anyone have any ideas?
I then had to load the words within a 'text1.txt' file and compare this with the banned words. If text1 contained a band word, the banned word is filtered out.
I was also given text2.txt, text3.txt and text4.txt. I needed to do the same with them all.
Here is what I have so far
http://i.gyazo.com/53ab68417ffc274a99767113d1c7c2b2.png
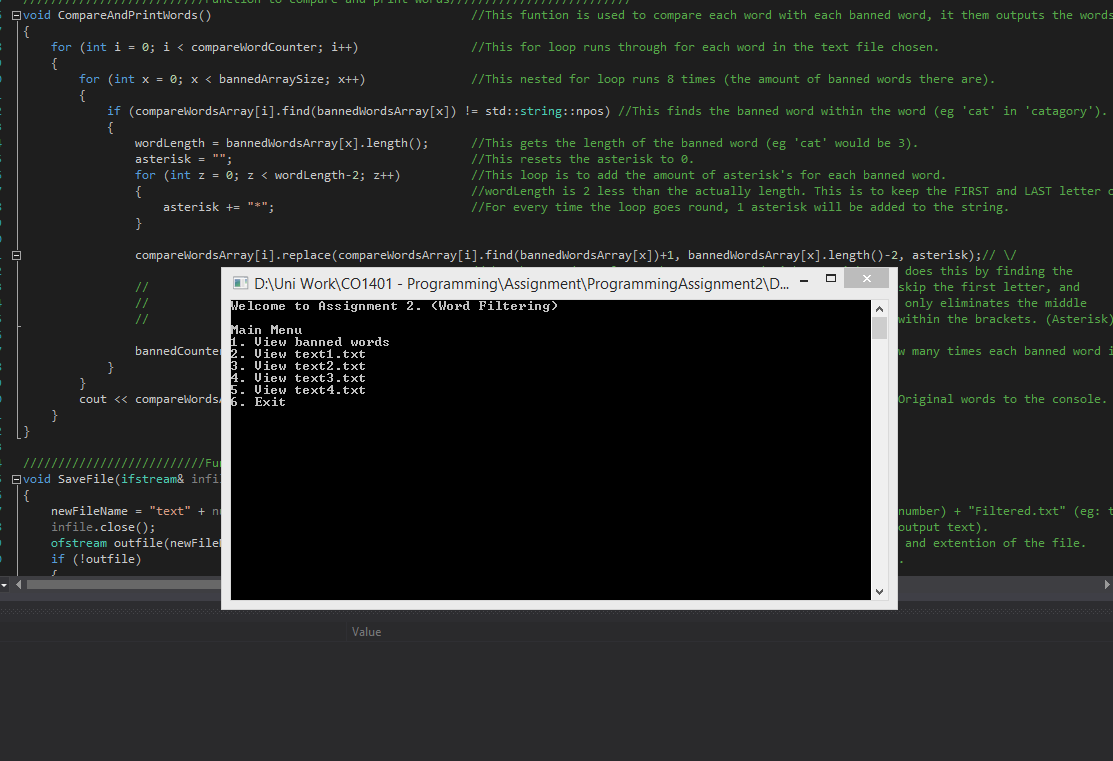{kind=link}
When i select '2' this is shown, the banned words filter perfectly.
http://i.gyazo.com/9fdb7086f8d54394cdcec8f071e606e5.png
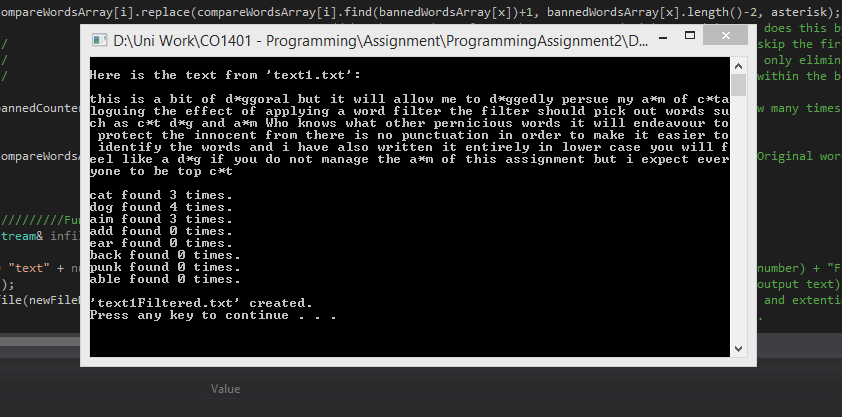{kind=link}
The Problem
I have been asked to do the following.
| • Calculate the 10 most frequent words from the text files. Do this for each individual file and for the files as a whole. • List the top 10 words alphabetically. • Calculate how times each banned word was found, both as a whole word and as a sub-string. |
I currently have no idea how to go about this.
Anyone have any ideas?
Last edited on
Problem:
# Read every word in the file and count them all. The 10 highest counts win.
# You have to consider whether case-sensitivity, are "Word" and "WORD" the same word?
std::map would be nice for this, but there's the question of sorting by value which you can't do. There's boost::multi_index_container which could help, but this works too -
store everything in a map, this is useful for the frequency part
copy everything to a vector of pairs, this is useful for the sorting part
sort the vector based on frequency, i.e. pair::second
display results
# Read every word in the file and count them all. The 10 highest counts win.
# You have to consider whether case-sensitivity, are "Word" and "WORD" the same word?
std::map would be nice for this, but there's the question of sorting by value which you can't do. There's boost::multi_index_container which could help, but this works too -
store everything in a map, this is useful for the frequency part
copy everything to a vector of pairs, this is useful for the sorting part
sort the vector based on frequency, i.e. pair::second
display results
|
|
FWIW, I run into this problem pretty frequently at work. If you can get the words into individual lines of a file then a unix system can do it easily:
sort - sort the lines
uniq -c - collapse identical lines and precede them with the number of times they occur
sort -n - now sort the result numerically.
tail -10 - print the last 10 lines of the sorted result: that's the 10 most frequent lines.
sort | uniq -c | sort -n | tail -10sort - sort the lines
uniq -c - collapse identical lines and precede them with the number of times they occur
sort -n - now sort the result numerically.
tail -10 - print the last 10 lines of the sorted result: that's the 10 most frequent lines.
@tipaye
Looks VERY complicated, I do not understand the half of it, I shall try to understand it and impliment it tho thanks for the reply.
and @dhayden
what is unix system?
Looks VERY complicated, I do not understand the half of it, I shall try to understand it and impliment it tho thanks for the reply.
and @dhayden
what is unix system?
Topic archived. No new replies allowed.